
Generative Artificial Intelligence and the Future of Health Economic Modeling
William Rawlinson, MPhysPhil, Estima Scientific, London, England, UK

Introduction
Generative artificial intelligence (AI) is a field within AI aimed at generating new content (text, image, video, and audio). The field has progressed rapidly in recent years with the development of large language models (LLMs)—large-scale, pretrained, statistical language models based on neural networks.1
In the past 12 months, generative AI has emerged as a hot topic in the health economics and outcomes research (HEOR) community. There is a recognition that LLMs offer unprecedented opportunities for enhancing the efficiency, speed, and quality of our work.
So, what’s the fuss about? Firstly, the application of LLMs in HEOR encompasses a wide range of problems that were not previously amenable to AI. Traditionally, AI was limited to classification and prediction.2 However, LLMs can generate text, code, image, audio, and even video content. While classification and prediction were useful in certain domains of HEOR, these new capabilities are applicable across all domains.
"In the past 12 months, generative AI has emerged as a hot topic in the health economics and outcomes research community."
Secondly, LLMs have comparatively low barriers to use. Traditional AI models were developed and optimized for highly specific tasks. LLMs such as OpenAI’s GPT-4o have demonstrated an extensive degree of versatility, performing tasks as varied as debugging code, translating text, and interpreting images. Given the above, it’s no wonder there is a rush to explore applications for LLMs across HEOR.
LLMs are expected to have a large impact in health economic modeling. The process of building, adapting, reporting, and quality controlling health economic models is often repetitive, time-consuming, and prone to human error. Through application of LLM-based methods, there are opportunities to enhance the efficiency, speed, and accuracy of our modeling. This article aims to shed light on the future of LLMs in health economic modeling. It focuses on the findings of a 2024 study that evaluated the capabilities of GPT-4 in constructing health economic models and concludes with a discussion of what we can expect in the years to come.
A note on using LLMs
Before getting started, it’s important to touch on the different ways in which LLMs can be used. Most health economists will have interacted with LLMs through a web interface such as ChatGPT. This can be extremely useful for Q&A support; however, more advanced approaches are required to solve complex problems such as those involved in health economic modeling. Just as humans struggle to answer complex questions straight away, an LLM’s performance is generally optimized when problems are broken into steps, which can be focused on one at a time.
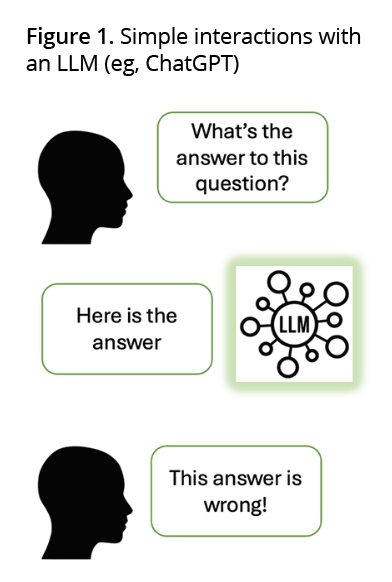
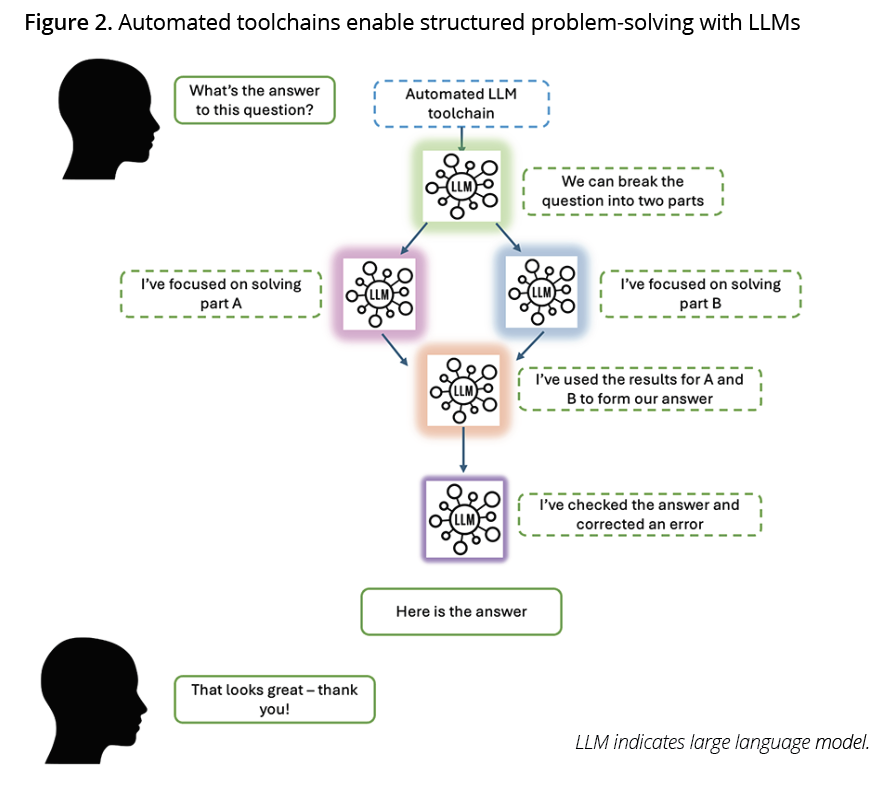
Application programming interface calls (API calls) can be used to build automated LLM toolchains that enable structured approaches to problem solving. Figures 1 and 2 demonstrate 2 different approaches to asking an LLM a question.
"LLMs are expected to have a large impact in health economic modeling. Through application of LLM-based methods, there are opportunities to enhance the efficiency, speed, and accuracy of our modeling."
Figure 1 visualizes a simple approach, mirroring interactions with ChatGPT. Figure 2 visualizes an automated toolchain, which enables structured problem solving. The colored LLMs in Figure 2 represent that models primed with different instructions and context can be used at different points in the chain, optimizing their performance on a specific subtask. For those who are interested in applied LLM methods, a good place to start is: https://platform.openai.com/docs/guides/prompt-engineering/six-strategies-for-getting-better-results.
Are LLMs good modelers?
In March 2023, GPT-4 was released. This was widely regarded as a step change in the capabilities of LLMs. GPT-4 demonstrated impressive abilities in writing code, and this inspired my colleagues and me, as well as our collaborators at Bristol Myers Squibb, to investigate the capabilities of GPT-4 in health economic modeling. After several months of testing and refinement, we presented our research at ISPOR Europe, and subsequently published in Pharmacoeconomics Open.3
"Rather than test GPT-4 directly, we developed an automated toolchain for partitioned survival modeling in R."
The aim of our research was to assess whether GPT-4 could program 2 published health economic analyses in R based on text instructions describing the assumptions, methods, and parameter values that should be used. We focused on R rather than Microsoft Excel because it’s an innately more LLM-friendly format (more on this later). The health economic models were partitioned survival models in non–small-cell lung cancer and renal cell carcinoma that were originally developed in Microsoft Excel.4,5 As any modeler knows, programming a cost-effectiveness model is a complex problem. Therefore, rather than test GPT-4 directly, we developed an automated toolchain for partitioned survival modeling in R (see Figure 2). Our chain of LLM interactions used separate instances of GPT-4 primed with contextual knowledge and instructions relevant to specific aspects of health economic modeling. For example, coding the drug acquisition cost calculations or writing code to construct a trace.
To test the performance of the toolchain, we manually developed a set of text instructions (or ”prompts”) describing the assumptions, methods, and parameters of each cost-effectiveness model (see Figure 3). The prompts were supplied and complete R scripts for each cost-effectiveness model were automatically generated without human intervention. As the output of an LLM can vary, we generated 15 scripts for each health economic model to test variability.
The findings of our study were very promising. The AI-generated cost-effectiveness models were created rapidly (average 834 seconds) and accurately (over 73% of scripts were completely error free, and error-free scripts replicated the published incremental cost-effectiveness ratios to within 1%).
Hallucinations are an often-cited issue with LLMs. However, we found that creating a sufficiently structured toolchain, providing detailed prompts to describe the cost-effectiveness model design, and priming LLMs with contextual knowledge at each point in the chain, essentially eliminated this problem. Where errors were identified, the vast majority were minor and similar to errors that might be made by a human modeler. For example, omitting a conversion of time units.

What does this mean for health economic modeling?
The research described above demonstrates that given the right prompts, complex health economic models can be accurately programmed by LLMs in rapid timeframes. I believe this has significant implications for how we will build health economic models.
If LLM-based health economic modeling toolchains can be perfected, health economists could automatically program models (such as cost-effectiveness models or budget impact models) following conceptualization. Given that the capabilities of LLMs are continuing to improve, I think this is a strong possibility. Automation would enable rapid and efficient health economic model development and could reduce human error (a 2020 study found that virtually all human-built health economic models contain technical errors).6 In this scenario, health economists would write model specifications designed for LLMs and quality control AI-generated models. This level of efficiency could support routine exploration of alternative model structures, which are currently rarely performed due to associated costs. Further, short of full adoption, AI-generated health economic models could be used to efficiently perform double programming validation for human-built models.
Health economists can prepare for this future by getting hands-on with LLMs and learning their strengths and limitations. For example, experimenting with ChatGPT to write Excel formulae or provide comments on model code. Note that confidential information should not be submitted to public LLMs and any outputs should be checked by a human.
Regarding the acceptability of AI-programmed models, it should be noted that an AI-generated model is just as scrutable as a human-built model. All calculations, input values, and any other programming are visible and can be quality-controlled in the same manner.
Despite the promising indications, it’s important not to overstate what has been achieved so far. There is still much work to do. Chiefly, further studies are required to test the generalizability of LLM-based modeling toolchains across a greater number of disease areas, models, and model types. Developing and improving LLM-based toolchains is time-consuming and requires expertise. To realize the full potential of LLMs in health economic modeling, investment will be required.
"Given the right prompts, complex health economic models can be accurately programmed by LLMs in rapid timeframes."
Looking forward
So far, this article has focused on an important but narrow application of LLMs to health economic modeling. I’ll conclude by touching on some promising indications for applications in other areas.
Excel modeling
As mentioned above, R models are innately more “LLM-friendly” than Excel models. This is primarily because Excel models require a greater level of interpretation. Consider Figure 4. In the R model (right-hand side) there is no ambiguity as to what “50” represents; it is the value of the “drug_A_cost” variable. In the Excel model (left-hand side) we need to infer that “50” represents the cost of drug A through the spatial relationship between 2 cells. Despite this challenge, some promising early research has demonstrated the feasibility of using LLMs to adapt Excel-based cost-effectiveness models, see: https://tinyurl.com/5n8veatu. Integration of LLMs with Excel-based modeling is likely to rely on consistently structured, “AI-friendly” models.

Reporting
LLMs may also enable automated reporting pipelines for health economic models (see: https://tinyurl.com/4mmj224n). This could be a significant use-case due to the frequency at which model results are extracted (ie, for adaptations, scenario analyses, or when an error is found in the model).
Semiautomation
Finally, most applications I’ve discussed have focused on end-to-end automation (albeit with subsequent human quality control). A promising area that applications may focus on in the shorter term is semiautomation. This could be particularly relevant where complex processes contain repetitive, simpler tasks. For example, an LLM assistant could be used to construct particular elements of an Excel model (eg, input sheets) in real time during manual cost-effectiveness model construction.
References
- Minaee S, Mikolov T, Nikzad N, et al. Large Language Models: A Survey [Internet]. 2024. Accessed July 2024. https://arxiv.org/abs/2402.06196
- Padula WV, Kreif N, Vanness DJ, et al. Machine learning methods in health economics and outcomes research-the PALISADE Checklist: A Good Practices Report of an ISPOR Task Force. Value Health. 2022;25(7):1063–1080.
- Reason T, Rawlinson W, Langham J, Gimblett A, Malcolm B, Klijn S. Artificial intelligence to automate health economic modeling : A case study to evaluate the potential application of large language models. Pharmacoecon Open. 2024 Mar 1;8(2):191–203.
- Çakar E, Oniangue-Ndza C, Schneider RP, et al. Cost-effectiveness of nivolumab plus ipilimumab for the first-line treatment of intermediate/poor-risk advanced and/or metastatic renal cell carcinoma in Switzerland. Pharmacoecon Open. 2023;7(4):567–577.
- Chaudhary MA, Lubinga SJ, Smare C, Hertel N, Penrod JR. Cost-effectiveness of nivolumab in patients with NSCLC in the United States. Am J Manag Care. 2021;27(8):e254–e260.
- Radeva D, Hopkin G, Mossialos E, Borrill J, Osipenko L, Naci H. Assessment of technical errors and validation processes in economic models submitted by the company for NICE technology appraisals. Int J Technol Assess Health Care. 2020;36(4):311–316.
